Rémerveillement, à prix merveilleux


Tête : 0.98 W/kg
Tronc : 0.98 W/kg
Membres : 2.98 W/kg
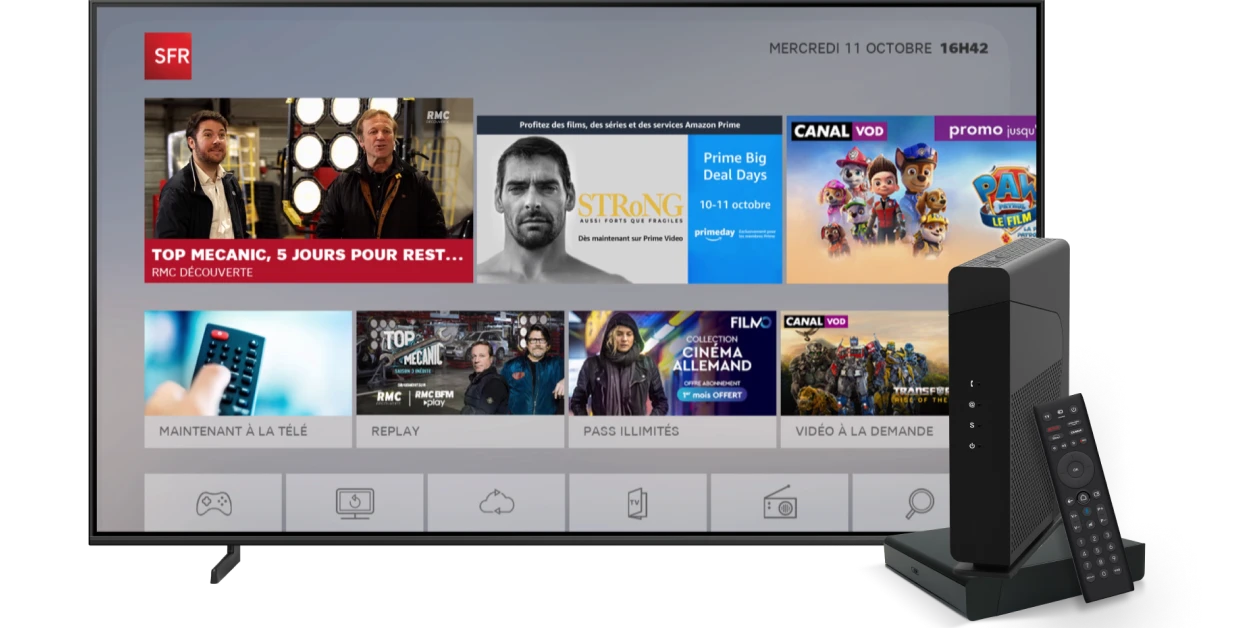
Pour être rassuré sur ce qui se passe chez soi


Galaxy AI  est là
est là
Galaxy S23



+8€/mois pendant 24 mois
Avec le forfait 210 Go 5G
Engagement 24 mois
Tête : 0.96 W/kg
Tronc : 1.3 W/kg
Membres : 2.42 W/kg




Le meilleur de SFR pour vous
Pourquoi choisir SFR ?




Les bons plans du moment

Tête : 0.97 W/Kg
Tronc : 0.98 W/Kg
Membres : 2.98 W/ Kg
Un numéro pas comme les autres.
 (1126 avis)
(1126 avis)+8€/mois pendant 24 mois
Avec le forfait 210 Go 5G

Mode grand spectacle activé
+8€/mois pendant 24 mois
Avec SFR Fibre Premium
Tronc : 1.2 W/kg
Membres : 2.49 W/kg
Vos Google Buds offerts.
+5€/mois pendant 24 mois
Avec le forfait 210 Go 5G

Au lieu de 64,98€/mois
Avec SFR Fibre Starter

Tronc : 0.92 W/kg
Membres : 2.15 W/kg
Vos Galaxy Buds FE offerts.
(7 avis)Avec le forfait 210 Go 5G
Engagement 24 mois
DAS Membre 0,36 W/Kg
DAS Tronc 0,15 W/Kg
Avec une large sélection d'accessoires.
L'actu par SFR
Voir toutes les actualités de SFR Actus


Forfait mobiles & smartphone, abonnement internet & TV Avec votre offre internet, bénéficiez d'un débit jusqu‘à 2Gb / seconde et des appels illimités vers les fixes et les mobiles. Après avoir testé votre éligibilité à la fibre, comparez les offres Fibre et ADSL et les fonctionnalités de nos box et décodeurs tv, dont la Box 4G et la Box 8 de SFR. Découvrez aussi l'offre Box + High Tech, un abonnement internet couplé à une smart TV Samsung ou Hisense ou encore une tablette Samsung
Vous pouvez également réaliser un test de débit avec la mire ADSL pour déterminer la vitesse réelle de votre bande passante, ou obtenir des informations détaillées sur la technologie fibre optique.
Chez SFR, profitez dès à présent de la nouvelle offre Maison Sécurisée pour une surveillance complète de votre habitation. En partenariat avec Europ Assistance, bénéficiez d'une intervention rapide en cas d'intrusion par un professionnel de la sécurité agréé, d'une large gamme d’équipements de sécurité, ainsi qu’une application vous permettant de piloter votre système de surveillance où et quand vous voulez. En choisissant SFR pour sécuriser votre maison, personnalisez votre pack alerte vidéo qui comprend déjà : une centrale de sécurité, une caméra wifi, un détecteur de mouvement et un détecteur d’ouverture. Vous pourrez également ajouter une sirène intérieure ou un clavier et des badges pour tout contrôler depuis votre porte d'entrée.
Que vous recherchiez un forfait mobile adapté à vos usages ou un forfait international power boosté pour les voyageurs, vous trouverez forcément l’abonnement mobile qui vous convient. Des remises spéciales vous font économiser jusqu'à 15€ par mois et par ligne mobile si vous êtes client Box et Mobile chez SFR. De plus, vous pourrez partager tous vos gigas avec les membres de votre famille grâce à SFR Family.
SFR vous propose les derniers Téléphones pour votre forfait : les fans inconditionnels d’iPhone ne pourront pas passer à côté du dernier né de la marque à la pomme : l’iPhone 15. Découvrez sans plus attendre toutes les fonctionnalités supplémentaires comme l’intégration de la puce A17 Pro présente sur l’iPhone 15 Pro et sur l’iPhone 15 Pro Max, ainsi qu’un revêtement extérieur en titane sur ces deux modèles, pour une robustesse sans égal. Le dernier de la série, mais pas des moindres, est l’iPhone 15 Plus. Equipé d’un double appareil avancé avec un objectif principal de 48 Mpx et d’une autonomie les plus élevés de la marque Apple, comment résister ?
Chez SFR, profitez encore de la gamme antérieure et (re)découvrez l'iPhone 14, l'iPhone 14 Plus, l'iPhone 14 Pro et l'iPhone 14 Pro Max.
Parmi les meilleurs smartphones Android, découvrez toutes les nouveautés de la marque Samsung. Notamment avec le dernier venu : le Samsung Galaxy S24. Ce smartphone est un concentré des dernières innovations de la marque, avec un design résolument moderne. La gamme se complète avec le Galaxy S24 Ultra, qui se place en haut de l’affiche dans les smartphones premium, et avec le Samsung S24+, qui éblouit par son design, sa puissance et sa polyvalence photographique. (Re)découvrez également le Samsung Galaxy S23 FE qui offre des performances puissantes pour un prix réellement abordables. N’oublions pas que la marque sud-coréenne a marqué les esprits, avec les iconiques et fabuleux smartphones pliables : le Galaxy Z Flip5 et le Galaxy Z Fold5.
La marque Xiaomi propose également des smartphones très performants, notamment la toute dernière gamme qui comporte le Xiaomi Redmi Note 13, le Redmi Note 13 5G, le Redmi Note 13 Pro 5G et le Xiaomi Redmi Note 13 Pro+ 5G. Dans les nouveautés 2024, découvrez également le Xiaomi Redmi 13C, qui pour un téléphone d’entrée de gamme offre des fonctionnalités performantes. D’autres mobiles sortis en 2023 valent le détour également, comme le Xiaomi 13T et le Xiaomi 13T Pro, conçu avec Leica, pour vous offrir une expérience photographique exceptionnelle, mais également le Xiaomi 13 et le Redmi A2.
Pour changer de téléphone à prix vraiment malin, profitez de la reprise mobile, et bénéficiez d’un Bonus reprise jusqu’à 200€ sur les téléphones éligibles. Vous pouvez aussi commander votre téléphone sans forfait et débloqué tout opérateur. Retrouvez l'ensemble de notre catalogue mobile à l'achat aux meilleurs prix, avec en prime les téléphones reconditionnés (tout savoir sur les téléphones reconditionnés chez SFR), et les smartphones 5G. Enfin, retrouvez tous les modes d'emploi de vos téléphones préférés.
Pour être à la pointe de la technologie, n’hésitez pas à allier des accessoires mobiles à votre smartphone. Que serait l’iPhone 13 sans les Airpods ou les smartphones Samsung Galaxy Buds FE ? Découvrez tous les écouteurs et casques audio, ainsi que les enceintes Bluetooth en vente chez SFR. Aujourd’hui, ne passez pas à côté des montres connectées, des indispensables, comme les Apple Watch ou la Samsung Galaxy Watch 6. Et pour personnaliser votre mobile comme vous le souhaitez, n’oubliez pas de prendre une coque de téléphone ou une protection.
Être client SFR c'est bénéficier d'une excellente couverture réseau mobile couvrant près de 99% de la population en 4G / 4G+, et du réseau 5G dont SFR continue le déploiement sur le territoire français (voir aussi : qu’est-ce que la 5G ?).
Sport, Ciné, Séries
Vos programmes préférés sont disponibles dans l'offre TV de SFR : naviguez dans notre catalogue de chaînes parmi 5 thématiques. Zappez entre les rencontres sportives et les séries TV. Evadez-vous avec National Geographic et les émissions de voyage ou détendez-vous en famille avec les chaînes Jeunesse et Disney+. Regardez les meilleures séries sur Netflix, OCS, Amazon Prime Video, ou Canal+ et vivez le meilleur du sport avec l’abonnement RMC Sport + beIN Sport l’offre couplée à prix réduit.
Avec Cafeyn, retrouvez les grands titres de la presse française en illimité, une expérience de lecture unique disponible sur tous vos écrans. Enfin, avec SFR Actus retrouvez toute l'actualité ciné-séries, sport, divertissement, les actus sur les dernières technologies, ainsi qu'une rubrique guide avec des comparatifs smartphone et plus encore.
Mentions légales
*Offres soumises à conditions en France métropolitaine.
Conditions du casque :
Consulter les conseils pour la sécurité en ligne des enfants. Comptes pour des utilisateurs de 10 ans et plus.
Asgard’s Wrath 2 est destiné à un public adulte
Un crédit vous engage et doit être remboursé. Vérifiez vos capacités de remboursement avant de vous engager. Exemple pour l’achat d’un achat à 1229 € avec un crédit en 24X : Paiement comptant de 749 € puis 24 mensualités de 20,00 €/mois. TAEG fixe : 0%. Taux débiteur fixe de 0%. Montant total dû par l’emprunteur : 480 € (hors assurance facultative). Coût de l’assurance facultative de 0,82 € par mois en plus de la mensualité. Le taux effectif de l’assurance est de 0.17%. Sous réserve d’acceptation par FLOA. Vous disposez d’un délai de rétractation. Coût du crédit pris en charge par SFR. Voir conditions sur http://c.sfr.fr/credit
BONUS REPRISE : offre soumise à conditions, valable en France métropolitaine, réservée aux abonnés mobile SFR ou RED by SFR, pour l’achat d’un mobile éligible (hors mobile seul) associé à la reprise d’un ancien mobile sur sfr.fr ou redbysfr.fr. Versement du bonus reprise entre 40 jours et 60 jours après la validation de la commande. Conditions et détails dans les conditions particulières du bonus reprise.
REPRISE MOBILE : offre soumise à conditions, valable en France métropolitaine, sur les sites internet sfr.fr ou redbysfr.fr, permettant à un client de céder la propriété d'un ou de plusieurs téléphones mobiles (dans la limite de 3 par an) en contrepartie d'un paiement en numéraire par SFR ou par un repreneur, partenaire de SFR. Voir conditions et détails sur https://www.sfr.fr/offre-mobile/tarifs-conditions.
RESEAU 5G : Réseau 5G de SFR, en cours de déploiement, valable sous réserve de couverture avec offre et terminal 5G compatibles. Réseau 5G 3,5 Ghz ou 2100 MHZ disponible selon les communes des agglomérations couvertes. Détails de couverture sur https://www.sfr.fr/couverture . La 5G présente des performances différentes suivant les fréquences utilisées, débit descendant maximum théorique (association des fréquences 4G et 5G dans les zones couvertes) de 2 Gb/s en bande de fréquence 3,5Ghz et de 995 Mb/s en bande de fréquence 2100 Mhz. La 5G est accessible depuis l’étranger avec une offre SFR et un terminal 5G compatibles, dans la limite des zones couvertes par les réseaux 5G des opérateurs étrangers ayant conclu un accord d’itinérance. Les débits 5G à l’étranger dépendent des opérateurs locaux partenaires de SFR.
KIT MAIN LIBRE : L’utilisation d’un kit mains-libres est recommandée.
MOBILE DEBLOQUES : Tous nos mobiles sont désimlockés, que qui signifie qu’ils peuvent être utilisés avec la SIM d’un autre opérateur.
DAS : Le débit d’absorption spécifique (DAS) local quantifie l’exposition de l’utilisateur aux ondes électromagnétiques de l’équipement concerné. Le DAS maximal autorisé est de 2 W/kg pour la tête et le tronc et de 4 W/kg pour les membres. La mesure DAS tronc peut avoir été calculée par rapport à une certaine distance d'un organisme humain simulé. Reportez-vous à la brochure du constructeur.
PAIEMENT EN 4 FOIS SANS FRAIS : Offre soumise à conditions, réservée aux abonnés mobiles SFR, personnes physiques majeures, domiciliés en France métropolitaine ou dans les DOM et titulaires d’une carte bancaire (Mastercard ou VISA) valable au moins 3 mois après la date de conclusion du contrat de paiement échelonné. Facilité de paiement, sans frais, d’une durée inférieure ou égale à 90 jours, en 4 échéances dont la première intervenant obligatoirement au jour de l’achat. Offre valable pour tout achat d’un terminal mobile et d’accessoires mobiles (uniquement avec l’achat d’un mobile) pour un montant total compris entre 50e et 3000€ (frais de port inclus), accompagné de la souscription simultanée d’un forfait mobile SFR avec un engagement 12 ou 24 mois ou dans le cadre d’un renouvellement de mobile (hors mobile et accessoires nus). Sous réserve d’acceptation du dossier par FLOA BANK, Société Anonyme au capital de 41 228 000 euros - Bâtiment G7, 71 Rue Lucien Faure, 33300 Bordeaux, RCS Bordeaux 434 130 423, ORIAS n°07 028 160 (www.orias.fr), Entreprise soumise au contrôle de l’Autorité de Contrôle Prudentiel et de Résolution (ACPR) 4 Place de Budapest, CS 92469, 75430 Paris Cedex 09
https://www.floabank.fr/images/pdf/CB4X/Conditions-Gnrales-Vente-CB3X-CB4X.pdf
FACILITE DE PAIEMENT : Offre réservée aux abonnés SFR (hors client RED by SFR et SFR Business) titulaires d'un forfait mobile SFR éligible. Selon l’offre et l’équipement éligibles choisis, solution de facilité de paiement d’un montant maximum de 192€, permettant de payer mensuellement (3, 5 ou 8€ /mois) une part du prix de l’équipement mobile sur une durée maximale de 24 mois, sans frais. Limité à une seule offre par ligne mobile. En cas de résiliation de la ligne ou de changement d’offre vers une offre inéligible, l’abonné devra régler l’intégralité des mensualités restant dues par anticipation.
CREDIT EN 24 FOIS : Un crédit vous engage et doit être remboursé. Vérifiez vos capacités de remboursement avant de vous engager.
Exemple de financement d'un achat de 801€ avec un forfait SFR Avec un crédit affecté** en 24X : Paiement comptant de 81€ puis 24 mensualités de 30,00€/mois.TAEG fixe : 0%. Taux débiteur fixe de 0%. Montant total dû par l'emprunteur : 720€ (hors assurance facultative). Coût de l'assurance facultative de 1,23 € par mois en plus de la mensualité. Le taux effectif de l'assurance est de 0.17%. Coût du crédit pris en charge par SFR.
Offre soumise à conditions, réservée aux abonnés mobiles SFR, personnes physiques majeures, domiciliés en France métropolitaine ou dans les DOM. Offre valable pour tout achat d’un terminal mobile dont le financement est supérieur à 200€, accompagné de la souscription simultanée d’un forfait mobile SFR éligible ou dans le cadre d’un renouvellement de mobile (hors achat de terminaux mobiles nus). La dernière mensualité pourra être ajustée à la hausse comme à la baisse dans la limite de 0,50€.
SFR SA, 16 rue du Général Alain de Boissieu 75015 Paris - RCS paris N°343 059 564, ORIAS n° 12 065 393 (www.orias.fr) agit en qualité de mandataire non exclusif en opérations de banque et en services de paiement de FLOA et apportant son concours à la réalisation d'opérations de crédit à la consommation sans agir en qualité de Prêteur.
*Exemple indicatif et sans valeur contractuelle calculé sur la base d’une première échéance 30 jours après la date du financement.
**Sous réserve d'acceptation du dossier par FLOA, RCS BORDEAUX 434 130 434 - Immeuble G7, 71 Rue Lucien Faure, 33300 BORDEAUX. ORIAS n°07 028 160 (www.orias.fr). Vous disposez d’un délai légal de rétractation de 14 jours. Conditions en vigueur au 14/11/2023 et susceptibles de variation.
***Soit 0,17% du capital emprunté par mois pour un emprunteur de moins de 66 ans pour les garanties Décès, Perte Totale et Irréversible d’Autonomie (PTIA) et Incapacité Temporaire Totale de travail (ITT). Contrat souscrit par FLOA auprès de ACM VIE SA (SA au capital de 778 371 392 €– RCS STRASBOURG 332 377 597 – Siège social : 4 rue Frédéric-Guillaume Raiffeisen - 67000 STRASBOURG Adresse postale : 63 Chemin Antoine Pardon, 69814 TASSIN cedex) et SERENIS ASSURANCES SA (SA au capital de 16 422 000€ – RCS ROMANS 350 838 686 – Siège social : 25 rue du Docteur Henri Abel, 26000 VALENCE - Adresse postale : 63 Chemin Antoine Pardon, 69814 TASSIN cedex), entreprises régies par le Code des Assurances.